简介
在我向 ChatGPT 提问的时候,发现了这个框架。
简单学了下后,拿 B 站练练手
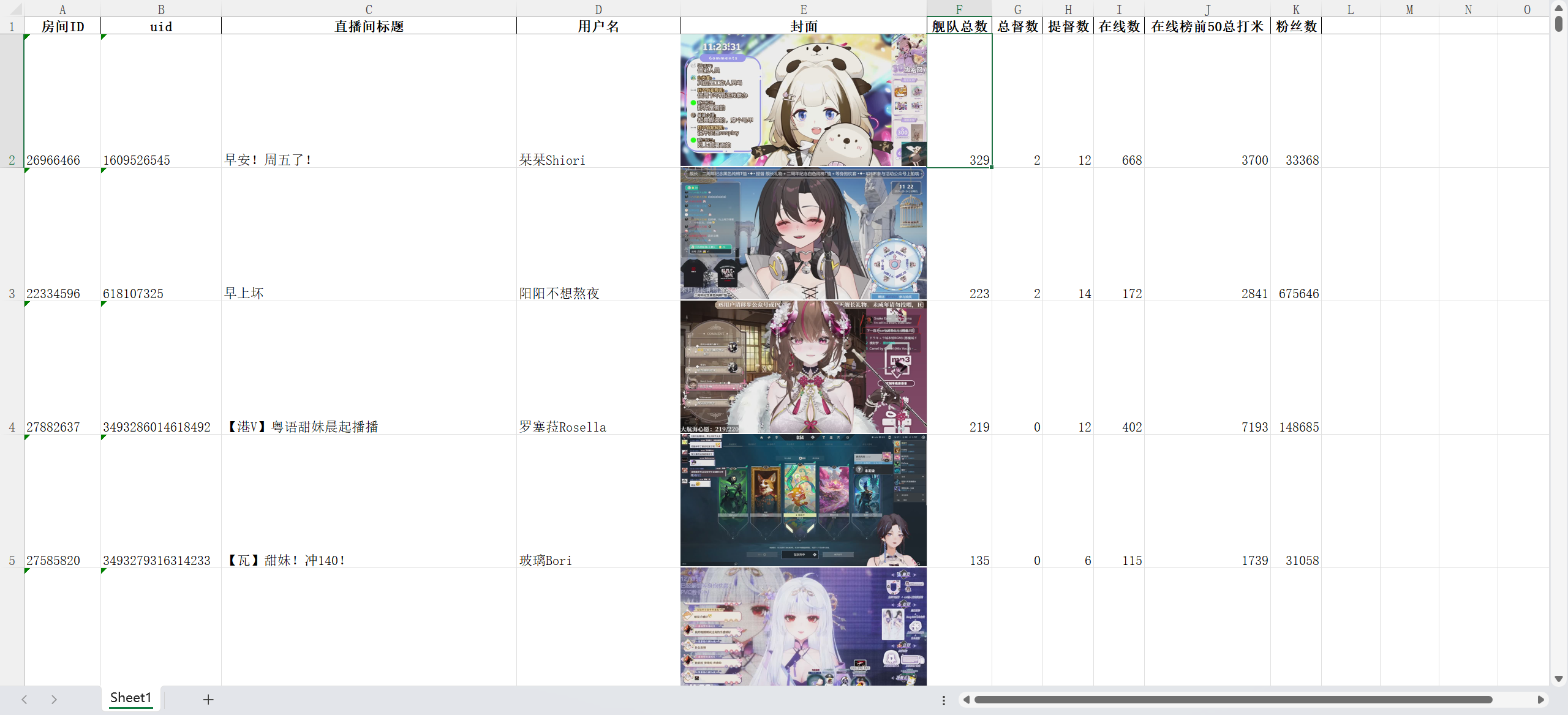
简单说下需求,就是把相应页数的主播的舰长数,在线数,粉丝数都取出来
收集待爬 URL
这一步太简单了,直接 F12 一开,然后看网络请求就完事儿了
B 站用的都是异步请求,而且 API 返回的都是 JSON,省了分析 HTML 的情况
总共有 4 个 URL
分别是
1 | 舰长榜 |
开始编程
创建工程
1 | scrapy startproject <工程名> |
创建文件
在 spiders 下创建一个 .py 文件
设置
B 站有对频繁的请求做限制,而且不允许 scrapy 访问,所以简单配置下线程和 User-Agent 头
打开 settings.py
1 | USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36" |
名称
关于类下面的 name 参数,意义就是调用爬虫的时候的名称,比如说我这里叫 getList,那么调用的时候就是
1 | scrapy crawl getList |
接收参数
本身 scrapy 就有 -a 参数可以传递命令行参数到爬虫
这么写就可以了
1 | def __init__(self, maxPage = 10, page = 1, *args, **kwargs): |
执行的时候就是
1 | scrapy crawl -a maxPage=30 getList |
针对多个 URL
多个 URL 可以直接在一个 parse 里分析完,我这里是分成了不同的 parse 去分析的,顺便简单说下关于数据传递的问题。
scrapy 是支持传递的,使用 meta 参数就可以将这个请求的结果带到下一个请求
1 | yield scrapy.Request('https://api.live.bilibili.com/xlive/general-interface/v1/rank/queryContributionRank?ruid={}&room_id={}&page=1&page_size=50&type=online_rank&switch=contribution_rank&platform=web'.format(result['uid'], result['roomid']), callback = self.parse_count, meta = result) |
下载图片
scrapy 本身是支持下载图片的,只需要在返回结果中加入一个 image_urls 列表。不过我这里导出结果不想更改,所以自己继承管道重写一个类。
编辑 pipelines.py
1 | import scrapy |
这个类就是会将封面下载到对应的文件夹内,然后把封面格替换成路径,方便等下插入图片
然后打开 settings.py,启用管道
1 | ITEM_PIPELINES = { |
这个注释掉的就是默认的下载图片管道
插入图片
excel 插入图片我用的是 pandas 的 xlsxwriter 引擎。
函数使用 insert_image,因为我需要图片跟着排序和筛选,所以 object_position 需要设置成 4。
1 | worksheet.insert_image(cell, img_path, { |
link 是给图片加超链接,这样点击图片就可以直接跳转到直播间
特别注意: 图片所在单元格必须比图片本身大,小了的话图片不会参与排序和筛选。
导出数据的问题
scrapy 是原生支持导出 json 的,但是我这个有图片,而且是需要筛选和排序的,所以我打算导出成 excel
也是编辑 pipelines.py,导出管道写在下载图片管道的上面
1 | class ExcelExportPipeline: |
整个类大致就是这样
数据处理
数据处理其实没什么好说的,打开网页请求下 API 看看要的数据在哪里,然后直接获取就行了。
整体代码
我之后上传 github,现在先不公开,我还得完善一下。
生成结果